TL;DR
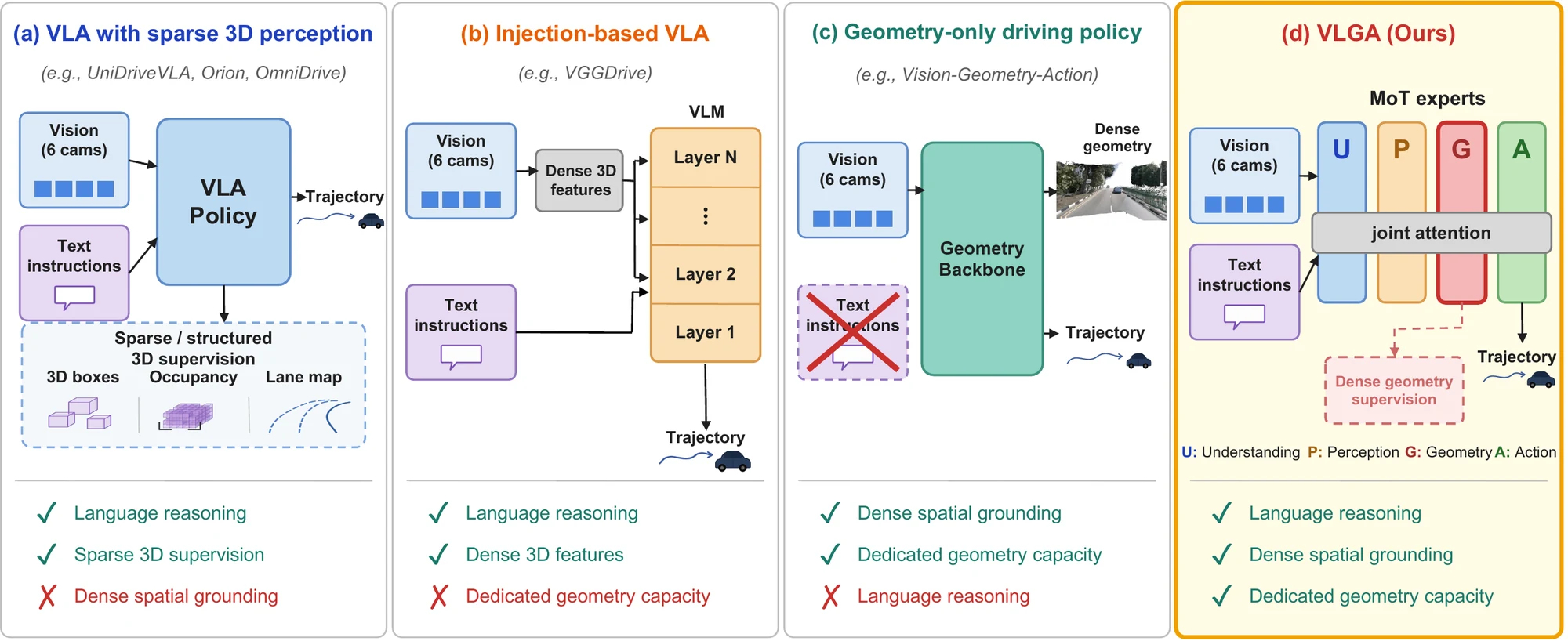
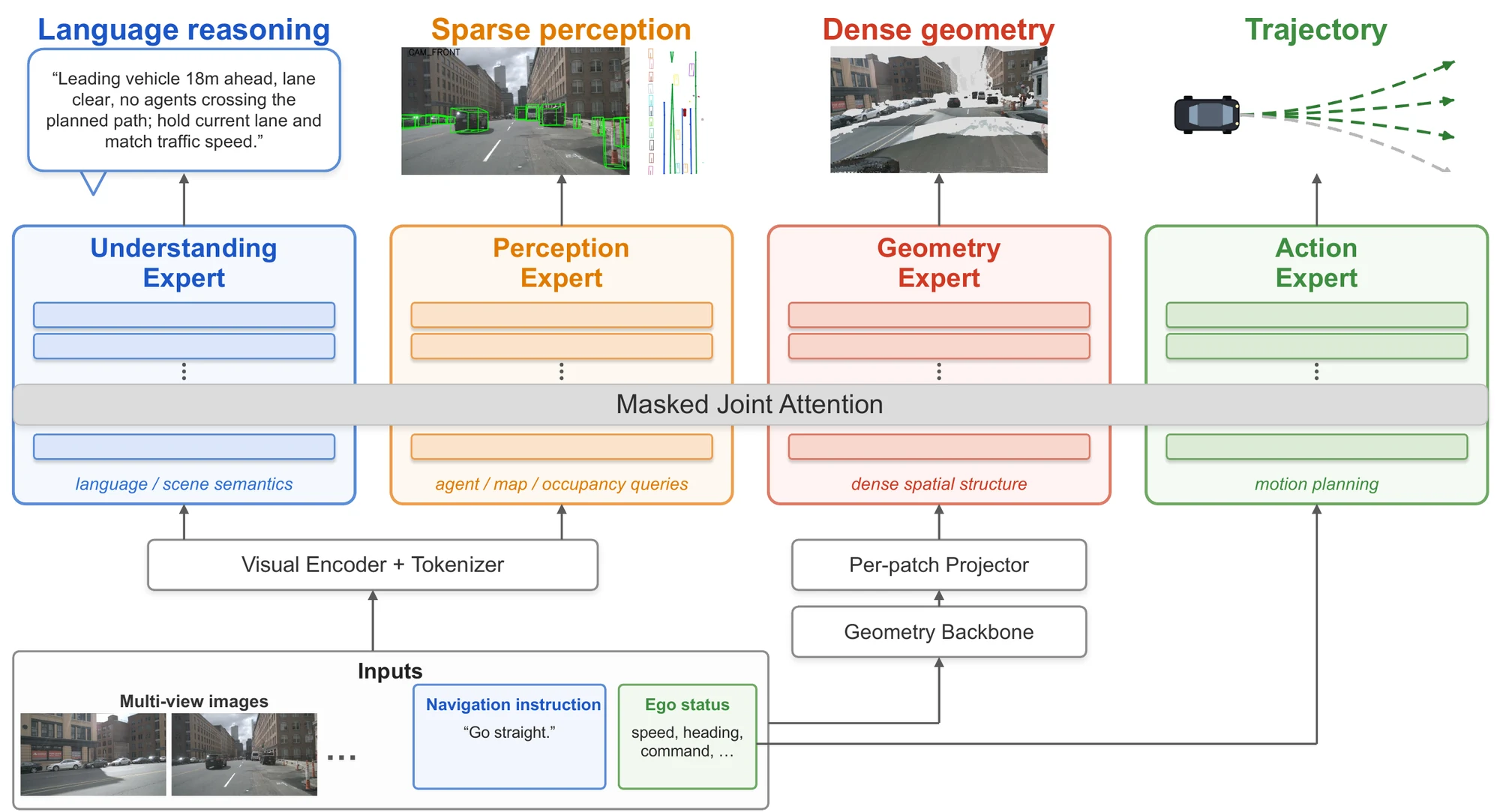
VLGA is the first vision-language-action model supervised to reconstruct the dense 3D world it drives through. Existing paradigms each miss one key capability: (a) VLAs with sparse 3D perception use structured supervision such as boxes, occupancy, and lane maps, but lack dense spatial grounding; (b) injection-based VLAs expose dense 3D features to the language model, but lack dedicated geometry capacity; (c) geometry-only driving policies provide dense grounding with dedicated capacity, but remove language reasoning. (d) VLGA preserves all three by introducing a parameter-isolated geometry expert supervised with dense geometry reconstruction.